A te oldalaidon szerepelnek másolt tartalmak? Ne vágd rá, hogy „nem”, mert lehet, hogy tévedsz. Szövegek keresőoptimalizálásával alapvetően nem szeretek sokat foglalkozni. Egy szövegíró ugyanis egy egyszerű szabály szerint él: úgy írj, mintha a Google nem létezne. Egy profi copywriter akkor is jól rangsoroló tartalmat ír, ha nem raksz elé kulcsszólistát. A tartalomduplikáció azonban egy olyan SEO-téma, aminek a legapróbb részleteit muszáj legalább egyszer tisztáznunk. Kezdjük azzal, hogy tisztázzuk a legnagyobb félreértést.
Nem, a Google NEM büntet a duplikációért
Bő egy hónapja Andrey Lipattsev, a Google senior stratégája egy élő videobeszélgetésben sokadszor
kijelentette, amit már többször is hallhattunk a keresőóriás képviselőitől: a Google-nél semmilyen policy nincs arra, hogy a duplikált tartalmakat büntessék. A büntetés nincs beépítve az algoritmusokba és nem is tartják elvből etikátlannak. Mindez tökéletesen érthető, tekintve, hogy a duplikáció általában „természetes” módon következik be, ahogyan ezt mindjárt látni fogod.
 Van ellenben szűrés.
Van ellenben szűrés. Ha több azonos tartalmat talál a kereső, akkor válogatni fog ezek között. Az algoritmus több száz tényezőt
vesz figyelembe, és ha nem talál olyat az egyező tartalmak között, amelyet eredetiként jelöltek meg, a legjobb minőségű találatot választja ki, a többit pedig elrejti a találati oldalról. (Lásd jobbra, a képet a
Moz.comtól vettük át.) Ezen sem lepődhetünk meg: a Google célja, hogy az emberek minél többször keressenek vele. Minőségi szolgáltatás kell tehát nyújtania, kielégíteni minél többek igényét – és ha egy találati oldalon tízszer ugyanaz szerepel, az egyáltalán nem javítja a felhasználói élményt. A Google tehát az eredetiséget és hozzáadott értékre mutató jeleket figyeli elsősorban: így igyekszik megtalálni a legjobb minőségű tartalmakat. Nincs szó büntetésről: a duplikált tartalom egyszerűen irrelevanciája miatt tűnik majd el a találatok közül. Az optimalizációt tekintve egy duplikált tartalom tehát jellemzően nem azért nem ér el majd jó – vagy bármilyen – helyezést, mert egyezés áll fenn, hanem mert nem elég jó, nincsen elég visszajelzés, a Google nem látja a hozzáadott értéket. (Ha Andreynek nem hiszel, Matt Cuttsnak esetleg már igen:
ő úgy becsüli, hogy a web teljes tartalmának 25-30 százaléka duplikáció – és ezzel nincs is semmi gond.) Ezzel együtt, idézek a Google súgójának ismétlődő tartalommal foglalkozó
oldaláról:
„Azokban a ritka esetekben, amikor a Google azt észleli, hogy az ismétlődő tartalom a rangsoraink manipulálásának és a felhasználóink megtévesztésének szándékával jelenik meg, a megtévesztésben részt vevő webhelyek indexelését és rangsorban elfoglalt helyét is módosítjuk a szükséges mértékben. Ezen problémák miatt webhelye visszaeshet a keresési eredmények rangsorában, vagy akár teljesen el is tűnhet a Google indexeiből, ami azt jelenti, hogy többé egyáltalán nem jelenik meg a keresési eredmények között.”
A duplikáció nem gond. A manipuláció igen.
Hogyan születik a duplikált tartalom?
A tartalomduplikációnak elképesztően sok oka lehet. Tartalommarketingesként az első, ami eszünkbe jutna, hogy valaki félreértelmezett költséghatékony keresőoptimalizálási kísérletként ugyanazt a tartalmat jeleníti meg egy sor blogon, amelyek mind a fő weboldalára linkelnek. A legtöbb esetben azonban nem black hat technikákról, és nem is lustaságról van szó: a legtöbb duplikációt egyszerűen a technika eredményezi.
Duplikáció az adatbázisban
Könnyen lehet, hogy egyszerűen az adatbázis eredményezi a duplikációt: a feltöltött tartalom kap egy egyedi azonosítót, ez azonban nem az URL, ahogyan egyből gondolnánk. A tartalomra egy időben számos különféle link mutathat a weboldalon belül, amelyeket a link aszerint generál, hogy éppen honnan érjük el azt – különféle címkékkel, kategóriákból, keresőből és így tovább. Hogyan jelenthet ez problémát? Képzeljük el, hogy egy ilyen adatbázisban publikálunk egy olyan tartalmat, amely népszerű lesz a bloggerek körében. A szakmai blogok felkapják, elkezdik hivatkozni – ettől azt várnánk, hogy az adott tartalom pozíciója javuljon a célzott keresőkifejezések találati oldalán. A kereső azonban dilemmába kerül, ugyanis ha nem figyelünk, könnyen lehet, hogy különféle címeket használnak majd, így ugyanazt a tartalmat mondjuk két-három eltérő URL-en hivatkozzák – ezek közül viszont a kereső csak egyet vesz majd figyelembe, és így jóval kisebb lesz a siker.
Kétélű optimalizálás
Elképzelhető az is, hogy a duplikált tartalom egyszerűen azért jelenik meg, mert a mobileszközökre, tabletekre és más okoskütyükre optimalizált oldalaink egy kicsit máshogy jelennek meg a keresőbotok számára: bizonyos esetekben azt látják, hogy adott egy desktopra és egy mobilra optimalizált oldal ugyanazzal a tartalommal. Alapesetben ez a platformcélzás miatt nem jelentene gondot, ha azonban a kereső nem tudja értelmezni azt, hogy tulajdonképpen csak egy félrecsúszott optimalizációs kísérletről van szó, akkor kárt szenvedhetünk emiatt.
Nyomtatóbarát oldalak
Szinte minden tartalmakat publikáló oldalon találhatunk egy nyomtatóbarát nézetet: egy egyszerűsített oldalt, amelyet könnyedén azonnal kinyomtathatunk. Itt nem jelennek meg a dizájn- és navigációs megoldások és a többi sallang, egyszerűen csak a szöveges tartalom. Ezeket az oldalakat értelemszerűen az eredeti tartalom oldaláról hivatkozzuk – és éppen ez a probléma. Ezeket a hivatkozásokat ugyanis a keresők botjai is megtalálják, benéznek mögéjük, és azt fogják látni, hogy egy újabb oldalon pontosan ugyanazt a tartalmat hivatkozzuk – amit akár úgy is értelmezhetnek, hogy black hat technikával igyekszünk javítani a rangsorolásunkon. Maga a másolt tartalom nem büntetendő ugyan, az etikátlan linképítésre azonban más szabályok vonatkoznak. A nyomtatóbarát oldalakat éppen ezért általában elrejtik a keresők elől, legalábbis így kellene – mégis sokszor jutok ilyen oldalakra a Google találati listájáról még a legnagyobb hazai hírportálok esetében is az eredeti tartalom helyett.
Kommentek több oldalra bontva
Gyakori jelenség WordPress-odalaknál, hogy a kommenteket több oldalra bontja a rendszer. Teljesen indokolt, hiszen egy sok száz kommentet tartalmazó oldal betöltése már igen lassú lehet, és tudjuk azt, hogy 3 másodpercnél hosszabb betöltési idő már komolyan rombolja a felhasználói élményt. Ebben az esetben viszont valahogy így fog kinézni az URL:
http://blogod.hu/posztod/comments-page-1/ http://blogod.hu/posztod/comments-page-2/
És így tovább – miközben az eredeti poszt minden oldalon megjelenik majd.
Eltérő URL-struktúrák, honosított oldalak
Duplikált tartalmat lát a kereső akkor is, ha az oldaladat több címen érheti el. Például:
blogod.hu http://blogod.hu https://blogod.hu http://www.blogod.hu
És ha .hu, .com, .eu és más domének alá ugyanazt az oldalt feltöltöd, akkor is ez a helyzet. Ha az URL változik, a Google is külön oldalként kezeli majd az eredményt, ez ilyen egyszerű.
„Minek annyit írni?”
Mégis, szövegírással foglalkozunk – a tartalmak másolásával gyakran találkozunk saját szakmánkban, amikor egyáltalán nem jóhiszemű hibáról, hanem lustaságról, a költségek optimalizálásáról vagy éppen egyszerű lopásról van szó. Ha a tartalommásolás tudatos és szándékos, még annak is rengeteg oka lehet. A híroldalak például rendszeresen vesznek át nagyobb szövegblokkokat egymástól, a hírügynökségektől vagy külső forrásokból, persze forrásmegjelöléssel együtt. Ez egy bevett, indokolt és teljesen etikus gyakorlat: hiszen ott van a forrásmegjelölés, és hozzáadott tartalom is keletkezik. Ha a saját tartalmaidat duplikálod, ezt most azonnal fejezd be: egy minőségi tartalmat elég egyetlen helyen közzétenned, nem kell minden oldalon szerepeltetned. Ha azt hiszed, hogy a kulcsszavak vagy a visszajelzések miatt javít majd a helyezéseden, hogy minden aloldaladon ott van néhány komplett blogbejegyzés, elkeserítelek: az eredmény éppen ennek ellenkezője lesz. Megint más esetről beszélünk, ha valaki lopni kezdi a tartalmaidat. Általában emiatt nem kell aggódnod olyan értelemben, hogy a másoló oldala aligha lehet sikeresebb a tiednél, ha megfelelően kommunikálsz. Szerzői jogi szempontból viszont már aggályos a kérdés, és érthető, hogy az értékes szellemi termékedet meg akarod védeni – ez viszont már nem a SEO vagy a tartalomkészítés, hanem a jog témakörébe tartozik. A lopást jelentheted a Google felé is – ezzel legalábbis a találati listáról eltávolítva azt. Erről lent a megoldások között olvashatsz bővebben.
Mi van a közösségi médiával?
A Facebookon, Twitteren, Tumblrön elképesztően sok olyan tartalmat találunk, amelyeket duplikációnak értékelhetünk. Ez a világ azonban máshogyan működik. A közösségi média aktívan ösztönzi a megosztásokat, hogy a tartalmakat eljuttasd még több emberhez, és ez egyáltalán nem minősül duplikációnak – még ha azzal jár is, hogy az azonos tartalom megjelenik újból és újból. Már csak azért sem, mert mindig ott található a hivatkozás az eredetire. A keresők egyes közösségi platformokra be sem látnak, ahová pedig igen, ott egyszerűen valószínűleg ugyanúgy rangsorolnak majd, és a legtöbb interakcióval bíró eredetit hozzák ki a találati oldalon.
Hogyan találd meg a duplikált tartalmakat?
Read More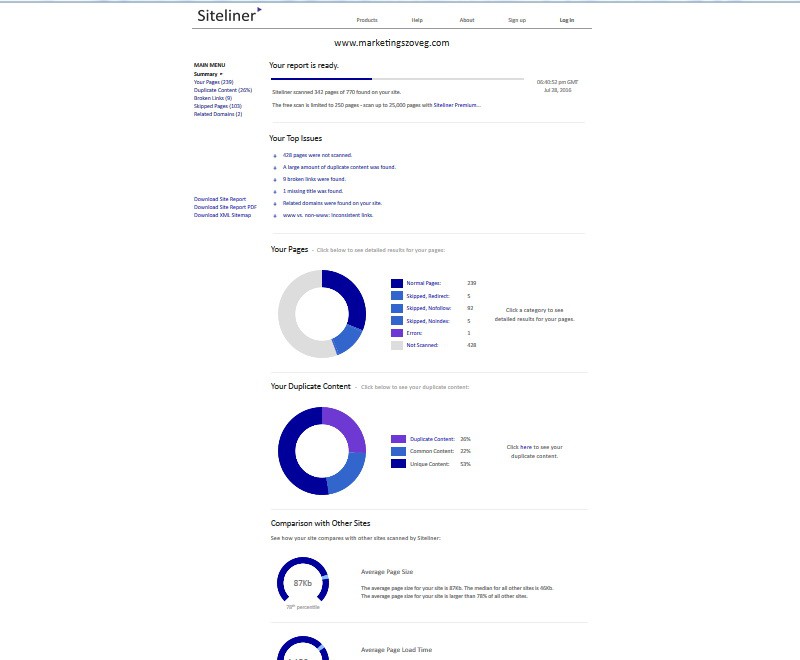 Az eszköz segítségével meglehetősen sok duplikátumot találtam a saját oldalunkon, bár a 26% egyáltalán nem kirívó. Különösen úgy nem, hogy a lista jellemzően a címke szerint szűrt bejegyzéseket listázó oldalakból áll – a posztok hajtás feletti részei a keresőoldalakon és a kategóriaoldalakon értelemszerűen sokszor ismétlődnek. Ezért tehát nem aggódom különösebben.
Az eszköz segítségével meglehetősen sok duplikátumot találtam a saját oldalunkon, bár a 26% egyáltalán nem kirívó. Különösen úgy nem, hogy a lista jellemzően a címke szerint szűrt bejegyzéseket listázó oldalakból áll – a posztok hajtás feletti részei a keresőoldalakon és a kategóriaoldalakon értelemszerűen sokszor ismétlődnek. Ezért tehát nem aggódom különösebben. 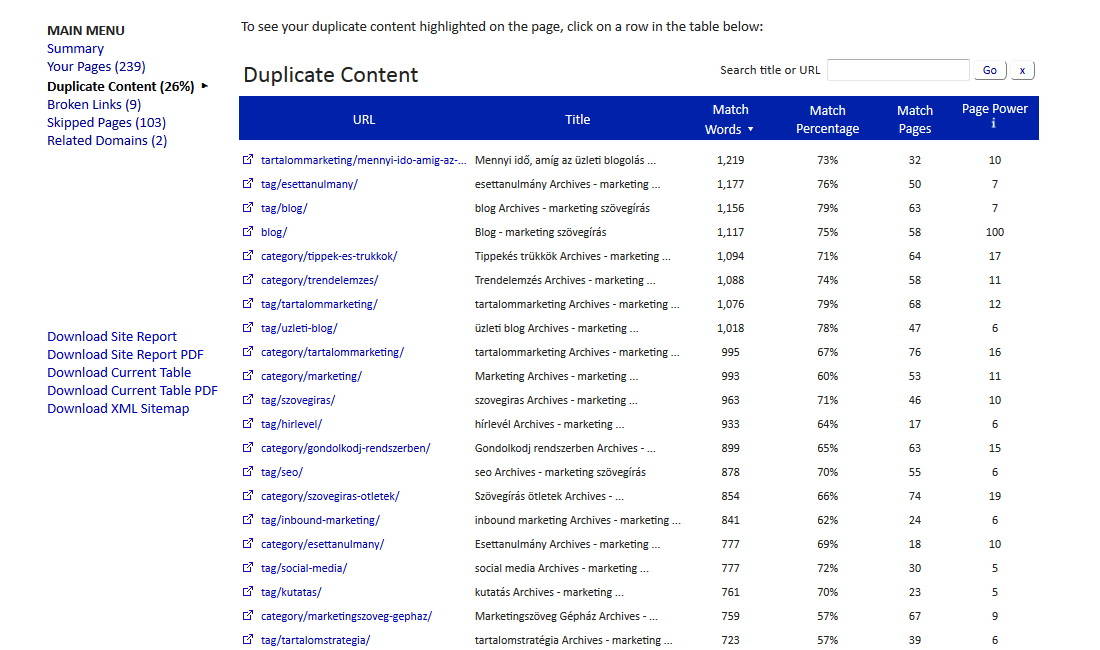 Ezen felül még egy sor adatot árul el a szolgáltatás: például, hogy egy átlagos oldal mérete nálunk 87 Kb (nagyobb az összes többi oldal 78%-ánál), és hogy a betöltési idő kicsit több, mint 1 másodperc (amivel jók vagyunk elvileg, hiszen az aranyszabály, hogy 3 másodperc fölé ne menj). Azt is látom, hogy egy átlagos oldalon 1481 szó szerepel – ebben persze benne van minden, az oldalsávval, lábléccel együtt, viszont a valós adat ennél minden bizonnyal magasabb, hiszen az előfizetői részbe nem lát be a Siteliner. Az oldalainkon 53% a teljesen egyedi tartalom aránya – ez ugye az, ami a keresőoldalakon már nem kerül listázásra: a posztok hajtás alatti része, a landing oldalak és a többi. A jelentést letölthetem PDF-ben, sőt, még egy oldaltérképet is kapok XML-ben. Ha fel akarod térképezni, hogy az oldalaidon hol találhatóak olyan duplikált tartalmak, amit a keresők is látnak, és egyben ennek okát is szeretnéd meghatározni (plusz egy rakás egyéb értékes információhoz jutni), akkor jó szívvel ajánlom neked a Sitelinert. Read More
Ezen felül még egy sor adatot árul el a szolgáltatás: például, hogy egy átlagos oldal mérete nálunk 87 Kb (nagyobb az összes többi oldal 78%-ánál), és hogy a betöltési idő kicsit több, mint 1 másodperc (amivel jók vagyunk elvileg, hiszen az aranyszabály, hogy 3 másodperc fölé ne menj). Azt is látom, hogy egy átlagos oldalon 1481 szó szerepel – ebben persze benne van minden, az oldalsávval, lábléccel együtt, viszont a valós adat ennél minden bizonnyal magasabb, hiszen az előfizetői részbe nem lát be a Siteliner. Az oldalainkon 53% a teljesen egyedi tartalom aránya – ez ugye az, ami a keresőoldalakon már nem kerül listázásra: a posztok hajtás alatti része, a landing oldalak és a többi. A jelentést letölthetem PDF-ben, sőt, még egy oldaltérképet is kapok XML-ben. Ha fel akarod térképezni, hogy az oldalaidon hol találhatóak olyan duplikált tartalmak, amit a keresők is látnak, és egyben ennek okát is szeretnéd meghatározni (plusz egy rakás egyéb értékes információhoz jutni), akkor jó szívvel ajánlom neked a Sitelinert. Read More